模型加载
到目前为止,我们一直在手动创建模型。简单的模型当然可以这么干,但如果是有成千上万多边形的复杂模型,那就行不通了。因此,我们将修改代码以利用 .obj 模型格式,以便可以利用 Blender 等软件来创建模型并运用到项目中。
lib.rs 文件中堆砌的代码已经很多了,让我们创建一个 model.rs 文件来安置所有模型加载相关的代码:
// model.rs
pub trait Vertex {
fn desc<'a>() -> wgpu::VertexBufferLayout<'a>;
}
#[repr(C)]
#[derive(Copy, Clone, Debug, bytemuck::Pod, bytemuck::Zeroable)]
pub struct ModelVertex {
pub position: [f32; 3],
pub tex_coords: [f32; 2],
pub normal: [f32; 3],
}
impl Vertex for ModelVertex {
fn desc<'a>() -> wgpu::VertexBufferLayout<'a> {
todo!();
}
}你会注意到这里有几点变化:
首先是 Vertex, 它在 lib.rs 中是一个结构体,而这里我们改为了 trait。我们会有多种顶点类型(模型、UI、实例数据等),Vertex 做为 trait 令我们能从其中抽象出 VertexBufferLayout 的创建函数,从而简化渲染管线的创建。
其次是 ModelVertex 中新增了 normal 字段。在讨论光照之前暂时不会用到它。
让我们来创建 VertexBufferLayout:
impl Vertex for ModelVertex {
fn desc<'a>() -> wgpu::VertexBufferLayout<'a> {
use core::mem;
wgpu::VertexBufferLayout {
array_stride: mem::size_of::<ModelVertex>() as wgpu::BufferAddress,
step_mode: wgpu::VertexStepMode::Vertex,
attributes: &[
wgpu::VertexAttribute {
offset: 0,
shader_location: 0,
format: wgpu::VertexFormat::Float32x3,
},
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 3]>() as wgpu::BufferAddress,
shader_location: 1,
format: wgpu::VertexFormat::Float32x2,
},
wgpu::VertexAttribute {
offset: mem::size_of::<[f32; 5]>() as wgpu::BufferAddress,
shader_location: 2,
format: wgpu::VertexFormat::Float32x3,
},
],
}
}
}这与原来的 VertexBufferLayout 基本相同,只是为 normal 添加了一个 VertexAttribute。删除 lib.rs 中我们已不再需要的旧 Vertex 结构体,并在 RenderPipeline 中使用来自 model 的新 Vertex:
let render_pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
// ...
vertex: wgpu::VertexState {
// ...
buffers: &[model::ModelVertex::desc(), InstanceRaw::desc()],
},
// ...
});由于 desc 接口是定义在 Vertex trait 上的,因此需要先导入 Vertex,然后才能调用到该接口的具体实现。只需将导入代码放在文件顶部:
use model::Vertex;现在,我们需要一个用于渲染的模型。你可以使用自己的模型,我这也提供了一个模型及其纹理的 zip 压缩包 。我们将新建一个与 src 目录同级的 res 目录来安置这个模型。
访问资源文件
cargo 在构建并运行程序时会设置一个当前工作目录,该目录通常就是放置了 Cargo.toml 文件的项目根目录。资源(res)目录的路径会因项目的结构而异。本节教程示例代码的资源目录位于 code/beginner/tutorial9-models/res/。我们加载模型时可以使用这个路径,仅需在路径后拼上 cube.obj。这似乎很完美,可一旦修改项目的目录结构,写在代码里的路径就不可用了。
所以,我们通过修改构建脚本,将 res 目录复制到 cargo 创建可执行文件的位置来解决此问题,然后再从那里引用资源文件。创建一个 build.rs(构建文件的默认名称)文件并添加以下代码:
use anyhow::*;
use fs_extra::copy_items;
use fs_extra::dir::CopyOptions;
use std::env;
fn main() -> Result<()> {
// 这一行告诉 cargo 如果 /res/ 目录中的内容发生了变化,就重新运行脚本
println!("cargo:rerun-if-changed=res/");
let out_dir = env::var("OUT_DIR")?;
let mut copy_options = CopyOptions::new();
copy_options.overwrite = true;
let mut paths_to_copy = Vec::new();
paths_to_copy.push("res/");
copy_items(&paths_to_copy, out_dir, ©_options)?;
Ok(())
}确保将 build.rs 放在与 Cargo.toml 相同的目录中,只有这样,在项目构建时 cargo 才能此运行构建脚本。
OUT_DIR 是一个环境变量,cargo 用它来指定应用程序将在哪里构建。
还需修改 Cargo.toml 来让构建脚本能正常运行,在构建依赖([build-dependencies])配置里添加以下依赖项:
[build-dependencies]
anyhow = "1.0"
fs_extra = "1.3"从 WASM 访问文件
遵循 WASM 规范,你不能在 Web Assembly 中访问用户文件系统上的文件。所以,我们利用 web 服务来提供这些文件,然后使用 http 请求将文件加载 到代码中。让我们创建一个名为 resources.rs 的文件来处理这个问题,创建两个函数分别用于加载文本文件和二进制文件:
use std::io::{BufReader, Cursor};
use cfg_if::cfg_if;
use wgpu::util::DeviceExt;
use crate::{model, texture};
#[cfg(target_arch = "wasm32")]
fn format_url(file_name: &str) -> reqwest::Url {
let window = web_sys::window().unwrap();
let location = window.location();
let base = reqwest::Url::parse(&format!(
"{}/{}/",
location.origin().unwrap(),
option_env!("RES_PATH").unwrap_or("res"),
))
.unwrap();
base.join(file_name).unwrap()
}
pub async fn load_string(file_name: &str) -> anyhow::Result<String> {
cfg_if! {
if #[cfg(target_arch = "wasm32")] {
let url = format_url(file_name);
let txt = reqwest::get(url)
.await?
.text()
.await?;
} else {
let path = std::path::Path::new(env!("OUT_DIR"))
.join("res")
.join(file_name);
let txt = std::fs::read_to_string(path)?;
}
}
Ok(txt)
}
pub async fn load_binary(file_name: &str) -> anyhow::Result<Vec<u8>> {
cfg_if! {
if #[cfg(target_arch = "wasm32")] {
let url = format_url(file_name);
let data = reqwest::get(url)
.await?
.bytes()
.await?
.to_vec();
} else {
let path = std::path::Path::new(env!("OUT_DIR"))
.join("res")
.join(file_name);
let data = std::fs::read(path)?;
}
}
Ok(data)
}在桌面环境里,我们是使用 OUT_DIR 环境变量来访问资源目录。
在 WASM 环境里,我们使用了 reqwest 来处理网络请求。需将以下依赖项添加到 Cargo.toml:
[target.'cfg(target_arch = "wasm32")'.dependencies]
# Other dependencies
reqwest = { version = "0.11" }还需要将 Location 功能添加到 web-sys 的 features 数组里:
web-sys = { version = "0.3", features = [
"Document",
"Window",
"Element",
"Location",
]}确保 resources 作为模块已添加到 lib.rs 中:
mod resources;使用 TOBJ 加载模型
加载模型是使用的 tobj 包。让我们将其添加到 Cargo.toml 中:
[dependencies]
# other dependencies...
tobj = { version = "3.2", features = [
"async",
]}在加载模型之前,我们需要有一个结构体来存放模型数据:
// model.rs
pub struct Model {
pub meshes: Vec<Mesh>,
pub materials: Vec<Material>,
}Model 结构体中 meshes 和 materials 两个字段都是动态数组类型。这很重要,因为一个 obj 文件可以包含多个网格和材质。下面我们接着来创建 Mesh 和 Material 结构体:
pub struct Material {
pub name: String,
pub diffuse_texture: texture::Texture,
pub bind_group: wgpu::BindGroup,
}
pub struct Mesh {
pub name: String,
pub vertex_buffer: wgpu::Buffer,
pub index_buffer: wgpu::Buffer,
pub num_elements: u32,
pub material: usize,
}Material 很简单,它主要有一个名称字段和一个纹理字段。名称更多是被用于程序调试。我们的立方体模型实际上有 2 个纹理,但其中一个是法线贴图,稍后 我们会介绍这些纹理。
说到纹理,我们还需在 resources.rs 中添加一个函数来加载 Texture:
pub async fn load_texture(
file_name: &str,
device: &wgpu::Device,
queue: &wgpu::Queue,
) -> anyhow::Result<texture::Texture> {
let data = load_binary(file_name).await?;
texture::Texture::from_bytes(device, queue, &data, file_name)
}load_texture 函数在为模型加载纹理会很有用,因为include_bytes! 宏要求我们在编译阶段就指定文件名称并加载纹理数据到构建的程序包内,而我们希望模型纹理能根据需要动态加载。
Mesh 包含一个顶点缓冲区、一个索引缓冲区和网格中的索引数,material 字段被定义为 usize 类型,它将用于在绘制时索引 materials 列表。
完成上面这些后,我们就可以加载模型了:
pub async fn load_model(
file_name: &str,
device: &wgpu::Device,
queue: &wgpu::Queue,
layout: &wgpu::BindGroupLayout,
) -> anyhow::Result<model::Model> {
let obj_text = load_string(file_name).await?;
let obj_cursor = Cursor::new(obj_text);
let mut obj_reader = BufReader::new(obj_cursor);
let (models, obj_materials) = tobj::load_obj_buf_async(
&mut obj_reader,
&tobj::LoadOptions {
triangulate: true,
single_index: true,
..Default::default()
},
|p| async move {
let mat_text = load_string(&p).await.unwrap();
tobj::load_mtl_buf(&mut BufReader::new(Cursor::new(mat_text)))
},
)
.await?;
let mut materials = Vec::new();
for m in obj_materials? {
let diffuse_texture = load_texture(&m.diffuse_texture, device, queue).await?;
let bind_group = device.create_bind_group(&wgpu::BindGroupDescriptor {
layout,
entries: &[
wgpu::BindGroupEntry {
binding: 0,
resource: wgpu::BindingResource::TextureView(&diffuse_texture.view),
},
wgpu::BindGroupEntry {
binding: 1,
resource: wgpu::BindingResource::Sampler(&diffuse_texture.sampler),
},
],
label: None,
});
materials.push(model::Material {
name: m.name,
diffuse_texture,
bind_group,
})
}
let meshes = models
.into_iter()
.map(|m| {
let vertices = (0..m.mesh.positions.len() / 3)
.map(|i| model::ModelVertex {
position: [
m.mesh.positions[i * 3],
m.mesh.positions[i * 3 + 1],
m.mesh.positions[i * 3 + 2],
],
tex_coords: [m.mesh.texcoords[i * 2], m.mesh.texcoords[i * 2 + 1]],
normal: [
m.mesh.normals[i * 3],
m.mesh.normals[i * 3 + 1],
m.mesh.normals[i * 3 + 2],
],
})
.collect::<Vec<_>>();
let vertex_buffer = device.create_buffer_init(&wgpu::util::BufferInitDescriptor {
label: Some(&format!("{:?} Vertex Buffer", file_name)),
contents: bytemuck::cast_slice(&vertices),
usage: wgpu::BufferUsages::VERTEX,
});
let index_buffer = device.create_buffer_init(&wgpu::util::BufferInitDescriptor {
label: Some(&format!("{:?} Index Buffer", file_name)),
contents: bytemuck::cast_slice(&m.mesh.indices),
usage: wgpu::BufferUsages::INDEX,
});
model::Mesh {
name: file_name.to_string(),
vertex_buffer,
index_buffer,
num_elements: m.mesh.indices.len() as u32,
material: m.mesh.material_id.unwrap_or(0),
}
})
.collect::<Vec<_>>();
Ok(model::Model { meshes, materials })
}渲染网格
在能够绘制完整模型之前,需要能绘制单个网格对象。让我们创建一个名为 DrawModel 的 trait,并为 RenderPass 实现它:
// model.rs
pub trait DrawModel<'a> {
fn draw_mesh(&mut self, mesh: &'a Mesh);
fn draw_mesh_instanced(
&mut self,
mesh: &'a Mesh,
instances: Range<u32>,
);
}
impl<'a, 'b> DrawModel<'b> for wgpu::RenderPass<'a>
where
'b: 'a,
{
fn draw_mesh(&mut self, mesh: &'b Mesh) {
self.draw_mesh_instanced(mesh, 0..1);
}
fn draw_mesh_instanced(
&mut self,
mesh: &'b Mesh,
instances: Range<u32>,
){
self.set_vertex_buffer(0, mesh.vertex_buffer.slice(..));
self.set_index_buffer(mesh.index_buffer.slice(..), wgpu::IndexFormat::Uint32);
self.draw_indexed(0..mesh.num_elements, 0, instances);
}
}把这些函数放在 impl Model 中也是可以的,但我觉得让渲染通道做所有的渲染(准确地说,渲染通道只是编码所有的渲染命令)更加合理,因为这是它的工作。这也意味着在渲染时必须先导入 DrawModel trait:
// lib.rs
render_pass.set_vertex_buffer(1, self.instance_buffer.slice(..));
render_pass.set_pipeline(&self.render_pipeline);
render_pass.set_bind_group(0, &self.diffuse_bind_group, &[]);
render_pass.set_bind_group(1, &self.camera_bind_group, &[]);
use model::DrawModel;
render_pass.draw_mesh_instanced(&self.obj_model.meshes[0], 0..self.instances.len() as u32);在开始绘制之前,需要实际加载模型并将其保存到 WgpuApp 实例。请在 WgpuApp::new() 中加入以下代码:
let obj_model = resources::load_model(
"cube.obj",
&device,
&queue,
&texture_bind_group_layout,
).await.unwrap();我们的新模型比之前的五角星要大一些,所以需要调整一下实例间的间距:
const SPACE_BETWEEN: f32 = 3.0;
let instances = (0..NUM_INSTANCES_PER_ROW).flat_map(|z| {
(0..NUM_INSTANCES_PER_ROW).map(move |x| {
let x = SPACE_BETWEEN * (x as f32 - NUM_INSTANCES_PER_ROW as f32 / 2.0);
let z = SPACE_BETWEEN * (z as f32 - NUM_INSTANCES_PER_ROW as f32 / 2.0);
let position = glam::Vec3 { x, y: 0.0, z };
let rotation = if position.length().abs() <= f32::EPSILON {
glam::Quat::from_axis_angle(glam::Vec3::Z, 0.0)
} else {
glam::Quat::from_axis_angle(position.normalize(), consts::FRAC_PI_4)
};
Instance {
position, rotation,
}
})
}).collect::<Vec<_>>();完成上面这些后,运行项目你就能看到如下渲染效果:
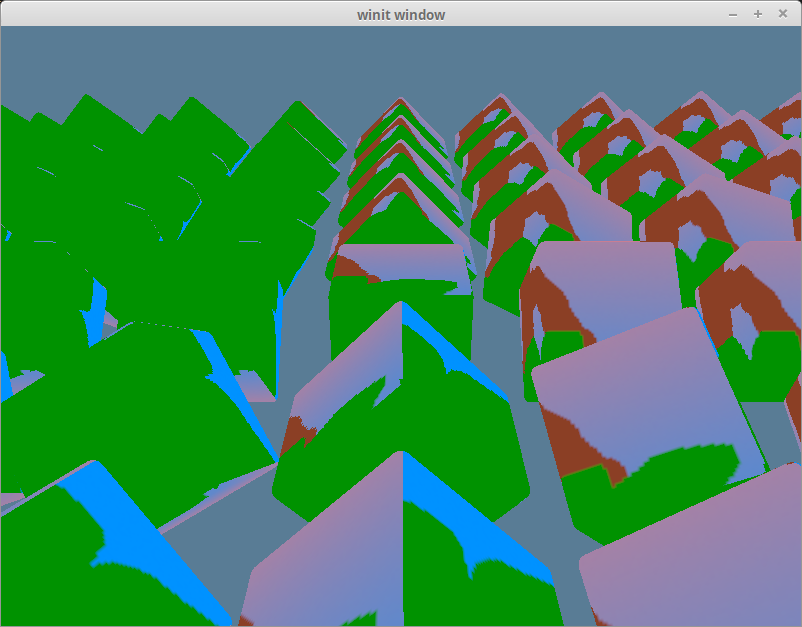
使用正确的纹理
我们目前看到的是还是之前的树纹理,它显然不是 obj 文件里的纹理。正确的纹理应该是下边这个:

这其中的原因很简单:尽管我们已经创建了纹理,但还没有创建一个绑定组来给 RenderPass,使用的仍然是 diffuse_bind_group。
如果想修正这一点,我们就需要使用材质的绑定组--Material 结构体的 bind_group 字段。
现在,我们来给 DrawModel 添加一个材质参数:
pub trait DrawModel<'a> {
fn draw_mesh(&mut self, mesh: &'a Mesh, material: &'a Material, camera_bind_group: &'a wgpu::BindGroup);
fn draw_mesh_instanced(
&mut self,
mesh: &'a Mesh,
material: &'a Material,
instances: Range<u32>,
camera_bind_group: &'a wgpu::BindGroup,
);
}
impl<'a, 'b> DrawModel<'b> for wgpu::RenderPass<'a>
where
'b: 'a,
{
fn draw_mesh(&mut self, mesh: &'b Mesh, material: &'b Material, camera_bind_group: &'b wgpu::BindGroup) {
self.draw_mesh_instanced(mesh, material, 0..1, camera_bind_group);
}
fn draw_mesh_instanced(
&mut self,
mesh: &'b Mesh,
material: &'b Material,
instances: Range<u32>,
camera_bind_group: &'b wgpu::BindGroup,
) {
self.set_vertex_buffer(0, mesh.vertex_buffer.slice(..));
self.set_index_buffer(mesh.index_buffer.slice(..), wgpu::IndexFormat::Uint32);
self.set_bind_group(0, &material.bind_group, &[]);
self.set_bind_group(1, camera_bind_group, &[]);
self.draw_indexed(0..mesh.num_elements, 0, instances);
}
}接下来修改渲染代码以使用正确的材质参数:
render_pass.set_vertex_buffer(1, self.instance_buffer.slice(..));
render_pass.set_pipeline(&self.render_pipeline);
let mesh = &self.obj_model.meshes[0];
let material = &self.obj_model.materials[mesh.material];
render_pass.draw_mesh_instanced(mesh, material, 0..self.instances.len() as u32, &self.camera_bind_group);全部修改完毕,就能看到如下渲染效果:
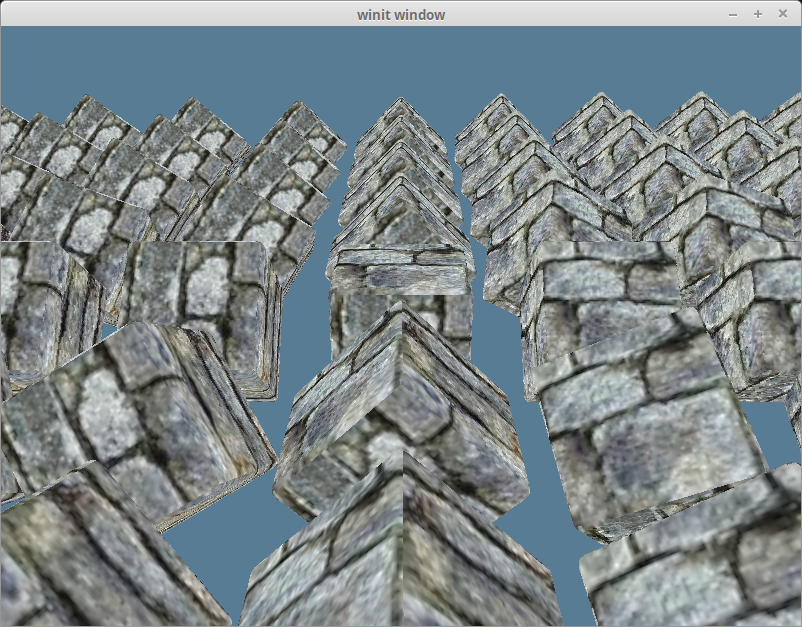
渲染完整模型
上边的代码直接指定了网格和对应的材质。这对使用不同的材质绘制网格很有用。
我们还没有渲染模型的其他部分,让我们为 DrawModel 新增一个函数,它将绘制模型的所有网格和对应的材质:
pub trait DrawModel<'a> {
// ...
fn draw_model(&mut self, model: &'a Model, camera_bind_group: &'a wgpu::BindGroup);
fn draw_model_instanced(
&mut self,
model: &'a Model,
instances: Range<u32>,
camera_bind_group: &'a wgpu::BindGroup,
);
}
impl<'a, 'b> DrawModel<'b> for wgpu::RenderPass<'a>
where
'b: 'a, {
// ...
fn draw_model(&mut self, model: &'b Model, camera_bind_group: &'b wgpu::BindGroup) {
self.draw_model_instanced(model, 0..1, camera_bind_group);
}
fn draw_model_instanced(
&mut self,
model: &'b Model,
instances: Range<u32>,
camera_bind_group: &'b wgpu::BindGroup,
) {
for mesh in &model.meshes {
let material = &model.materials[mesh.material];
self.draw_mesh_instanced(mesh, material, instances.clone(), camera_bind_group);
}
}
}lib.rs 中的代码也相应地修改一下以调用新的 draw_model_instanced 函数:
render_pass.set_vertex_buffer(1, self.instance_buffer.slice(..));
render_pass.set_pipeline(&self.render_pipeline);
render_pass.draw_model_instanced(&self.obj_model, 0..self.instances.len() as u32, &self.camera_bind_group);